


Open Source Reasoning. Let them learn
A prove that removing the human from the loop when training models can yield amazing results. Use AI to train better AI.

The biggest AI story this week? R1 (sorry Hispania 2040). Sure, it matches OpenAI's O1 in performance while running at 90-95% lower cost. And yes, it’s fascinating that a Chinese company is behind it. But what truly sets R1 apart is that it’s open source1—the first reasoning model to open the black box and let us AI geeks peek inside2. That’s fascinating.
You can try the model yourself here, really cool to look at how the model thinks. Difficult when you read its chain of thoughts not to anthropomorphize.

DeepSeek R1 Training
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin . The Bitter Lesson
LLMs to date relied on reinforcement learning with human feedback (RLHF), which means that humans (H) are in charge of defining what’s a good response (F) and what’s not a good response. R1 removes humans from the equation (almost completely3) and manages to significantly boost the performance of the model.
Our [DeepSeek] goal is to explore the potential of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure RL process.

What the DeepSeek team found is that as we reward a base model (in this case DeepSeek V3, a sparse model4) model for correct responses without human supervision, the model learns to allocate more time for “thinking”. Spending more time thinking doesn’t just mean generating longer responses. Instead, the model discovered how to use test-time compute more effectively—iterating on its reasoning, refining its steps, and improving accuracy without blindly increasing token count.
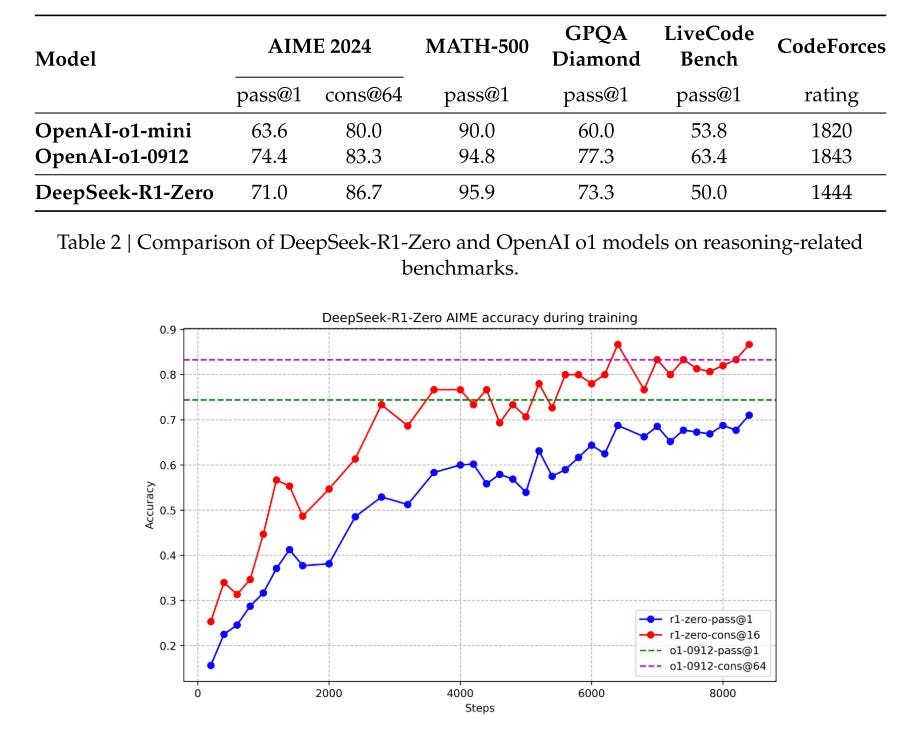
A particularly intriguing phenomenon observed during the training of DeepSeek-R1-Zero is the occurrence of an “aha moment”. This moment, as illustrated in Table 3, occurs in an intermediate version of the model. During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach.

Furthermore, the research team demonstrated that by using the outcomes of the R1-Zero model (the reasoning model), they could generate a dataset that allows them to distill other open-source models and improve their performance.

This achievement suggests that small models can “inherit” reasoning abilities from larger RL-trained models
Why is this important?
We are edging closer to the 'AlphaGo moment' for LLMs
The single biggest implication is that DeepSeek’s approach provides solid evidence that the AlphaGo moment that I described in my O3 post is closer and closer.
Reasoning is a new tool at our disposal to continue pushing frontier models' limits, effectively enabling a second scaling law. In this new reality, pre-training advancements (more data, more compute, better results) play along test-time compute (more time to return a correct response). It’s a self-reinforcing loop: reasoning produces better (synthetic) data — which was a limiting factor in pre-training gains- which builds stronger base models, which in turn fuels even more refined reasoning and so on. It’s a flywheel effect — one scaling law feeds the other, creating exponential progress.
In plain word, at the end of the day, if we want to achieve superhuman intelligence, having humans in the training loop becomes a limitation. But if models are able to self-improve using RL - and it has to be proven yet that this scales beyond human level intelligence for all areas - the only limitation to performance is in the compute capacity.
Scarcity drives innovation
DeepSeek has published in the last three months two impressive models despite the aggressive China Chip Ban, proving there are technical unhobblings that can lead to frontier level performance at a fraction of the cost. While GPT-4 cost is in the hundreds of millions, DeepSeek R1 and V3 have reportedly cost $5.6M. This opens two paths, one for smaller competitors that could create capable models (otherwise how is Anthropic going to compete with Stargate or X.ai), and two those with the massive resources, could probably unleash way higher performance.
The race for reasoning has begun
Until now, there were rumors on how Strawberry (internal code name for the O-family of models) was trained. A combination of RL and A* search. Now we think we know or at least we have a proven path that works. I expect more and more labs to quickly follow up with reasoning models and using distillation, start seeing smaller models with higher reasoning abilities.
It makes sense China does Open-source5
(This is an edit after a few days of discussions on the topic)
My first reaction is that it was ironic that China was the one doing open-source. But I have updated my views.
Aliexpress commoditized online shopping. Open-source is to LLMs what Aliexpress was for online shopping. China’s strengths is cost efficiency, scale, and infrastructure dominance, potentially allowing them to commoditize AI models and undercut U.S. firms that rely on proprietary monetization. Given U.S. chip restrictions, Chinese companies are forced to optimize for lower-cost training and inference, making open-source a natural strategy to drive rapid adoption and ecosystem growth.
There is no point on training anything worse than V3 and R1
Open-source is setting the minimum performance threshold for newly trained models. If you are going to train a model from scratch, there are very few reasons to do it unless you can surpass the best open-source model. Unless you can beat these models you are better off simply taking the OS and tunning it to your needs. Rumors are indeed, that Meta had a panic moment because R1 surpassed their new Llama model, and had to stop and re-think the strategy.
Who is DeepSeek by the way?
It’s ironic that we’re learning about the inner workings of reasoning from a Chinese company rather than from one called 'Open'. But who is behind DeepSeek.

From Perplexity:
DeepSeek, a groundbreaking Chinese AI startup founded in 2023, emerged as a spin-off from High-Flyer, one of China’s leading quantitative hedge funds. High-Flyer, established in 2015 by three Zhejiang University engineers, began as a disruptor in algorithmic trading and quickly became a top-tier quant fund managing $8 billion in assets. Known for its innovative use of AI and deep learning in finance, High-Flyer built cutting-edge infrastructure like the Fire-Flyer supercomputers to support its strategies. By 2021, all its trading relied on AI, earning comparisons to Renaissance Technologies. However, High-Flyer’s ambitions extended beyond finance; driven by founder Liang Wenfeng's vision of unraveling artificial general intelligence (AGI), the firm launched DeepSeek as an independent entity to focus on LLMs and AGI research. DeepSeek has since disrupted the AI landscape with cost-effective, high-performing models like DeepSeek-V3, leveraging High-Flyer’s culture of innovation and talent-first hiring practices. This transition underscores High-Flyer’s evolution from a quant fund into a pioneer of AI research and development.
Under MIT license
Main source for today’s post is the company’s white paper
There is some human involvement in the rejection-sampled process, where human feedback is provided to train in style
DeepSeek-V3 is the base model on which DeepSeek-R1 was trained. It’s a Mixture of Experts (MoE) model, meaning only certain parts of the network activate depending on the input. This makes it more efficient than fully dense models like GPT-4. While DeepSeek-V3 itself is a general-purpose model, R1 was built on top of it by applying reinforcement learning to specialize in reasoning.
R1 is not a fully open-source model, as the initial training data set for the base-model - at least to the best of my knowledge - is not a public dataset.