


Trial, Error, and Move 37: Understanding Big Tech's Path to AGI
From Reasoning to Action: How AI Labs Are Building the Path to AGI

In recent months, Sam Altman and other AI CEOs have shifted their public speaking tone, going from conservatively saying they don't know whether we'll reach AGI to clearly recognizing there is a path and a high chance we'll get there in the coming years.
I finally grokked the consequences of the new wave of post-training optimization after the DeepSeek developments, and I was going to write about it just to organize my thinking. But as it almost always happens, the writing took a turn, and pieces started falling into place. Although I may be completely wrong, especially because I'm keeping each of the individual pieces at 10,000 feet, I think the pattern that emerges from all the recent developments makes total sense, explains the public statements, justifies the investments, and points to that potential path.
The key argument I will make in these lines is that through our creation of intelligent machines, we’ve reached a point where they can accelerate human progress. However, for them to truly help us, they must do more than just mimic our knowledge. They must be able to contribute to the generation of novel insights by gaining the time to think (reasoning) and the ability to explore beyond text-only domains.
For now, let’s start by understanding the purest way of AI learning: reinforcement learning.
Introduction: The Path to AGI - Decoding the AI Labs’ Roadmap
To understand what reinforcement learning is (RL for short), I will start with a couple of videos that blew my mind a few years ago.
Or even an earlier example…
The videos are totally worth it, but in case you don’t want to watch them, what you see is that through playing thousands of games, a bunch of AI agents (those blue and red little people) can develop innovative strategies to beat their opponents. From knowing nothing to being a genius, by trial and error.
The key idea behind RL is that if you let the machines learn, and you have a clear, verifiable function - winning or losing a game - the machine will learn how to play subject to the game's rules. And if you give them enough time, they will learn to play better than a human and develop creativity. What everyone now refers to as the Move 37 in the Lee Sedol vs DeepMind's AlphaGo.
The rest of the post is about how we turn the world into a verifiable function. Bear with me.
The Leap to Large Language Models: From Prediction to Intelligence
LLMs are in some ways no different than those agents in the videos above; LLMs are deep neural networks that, through millions of iterations, learn to optimize their winning-or-losing function, which in this case is predicting the next word (token1) correctly. The beauty and surprise is that with enough data and compute, what begins as a simple word predictor (GPT-2) starts to show emerging capabilities. Now, the model can predict the next word correctly in a text that has been seen before (information compression), but more importantly, solve problems that have not been seen before (information creation).

Since GPT-2 demonstrated the power of scaling laws, most AGI Labs efforts were directed towards the pre-training phase. Teaching more and more of the available text to the LLMs, pushing farther the scaling law and going from thousands of dollars to hundreds of millions for each new generation.
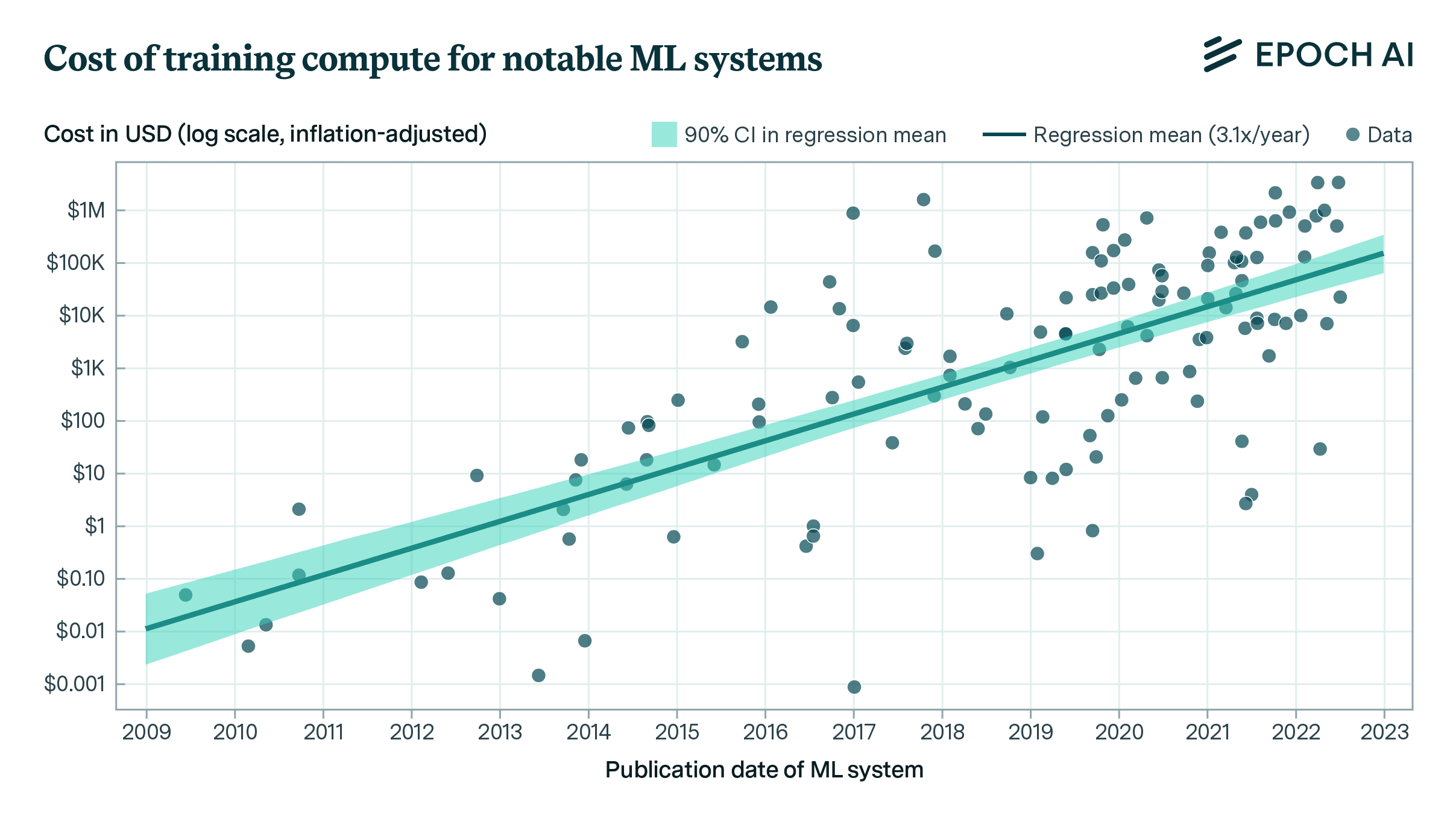
All this progress left us at a fascinating point where top AI models have essentially devoured all the text data we can throw at them. Sure, expanding into video and audio will push the boundaries further, but here's the thing – even these new data types alone won't be enough to crack the AGI puzzle.
The question then becomes: how or even what we should continue teaching the models?
We need to create high-quality data for the models to continue learning. We need to let them learn. To do so two paths opened ahead of us: Inference-Time-Compute and agentic interactions, and both of them require something very important, context, so before understanding each of these on its own let’s understand why context matters.
The Context Window
LLMs have no memory; the only way an LLM communicates with the external world is via the context window. Think of the context window as the model's short-term chalkboard. Everything you type—your questions, follow-ups, even little hints—gets written on this board, and that's all the model sees when it crafts its reply. Unlike humans, LLMs don't have long-term memory; they rely entirely on what’s visible in the context window to understand and continue the conversation. In short, it's the only bridge the model has to your world, and its size directly impacts how much of the conversation it can keep track of.
Why is this important? Imagine waking up with every discovery and invention of the past at your fingertips—only to have it all erased by nightfall. You’d tap into endless ideas during the day, but each evening, your hard-won wisdom would vanish. That’s the current state of LLMs: they draw on all our knowledge yet remain shackled by a fleeting context window. The next leap in AI was when we found a way to bridge that daily reset, transforming transient insights into enduring innovation.
This limitation hit hard in practical terms. When we tried to let these models really think or tackle complex tasks independently, they kept bumping into their memory ceiling. Imagine trying to write a symphony but only being able to see one measure at a time – that's what it's like for an LLM trying to reason deeply or learn to navigate the web with a limited context window. By the time they're getting somewhere interesting, their mental whiteboard is already full.
And as with most AI problems, this is a problem of the past. We are currently enjoying 1M token windows, which to put it in context, you could drop the entire Harry Potter series and would still have space to ask for a bunch of new magic spells. It’s not infinite, but give us far more wiggle room than the initial GPT’s 500 tokens.
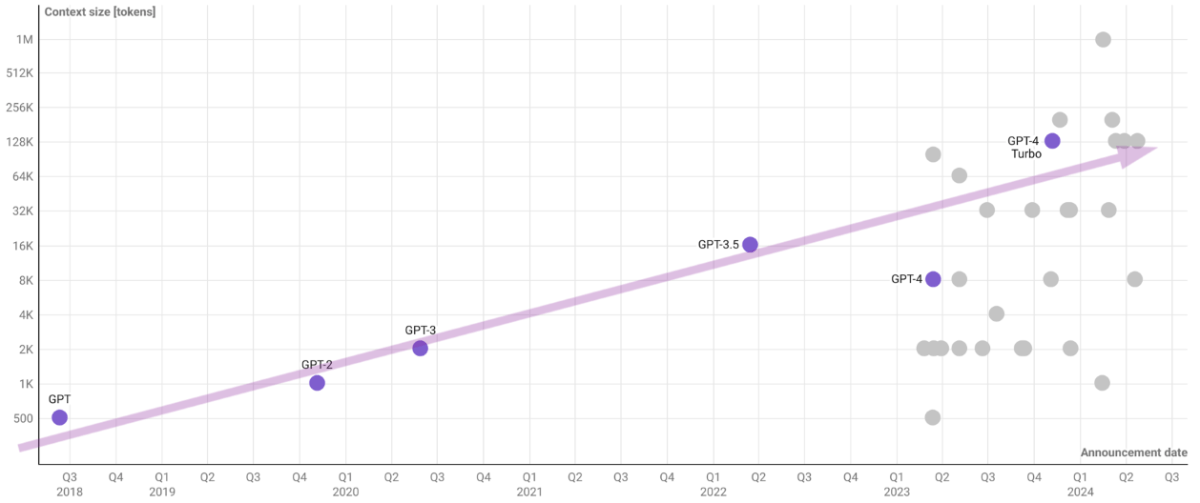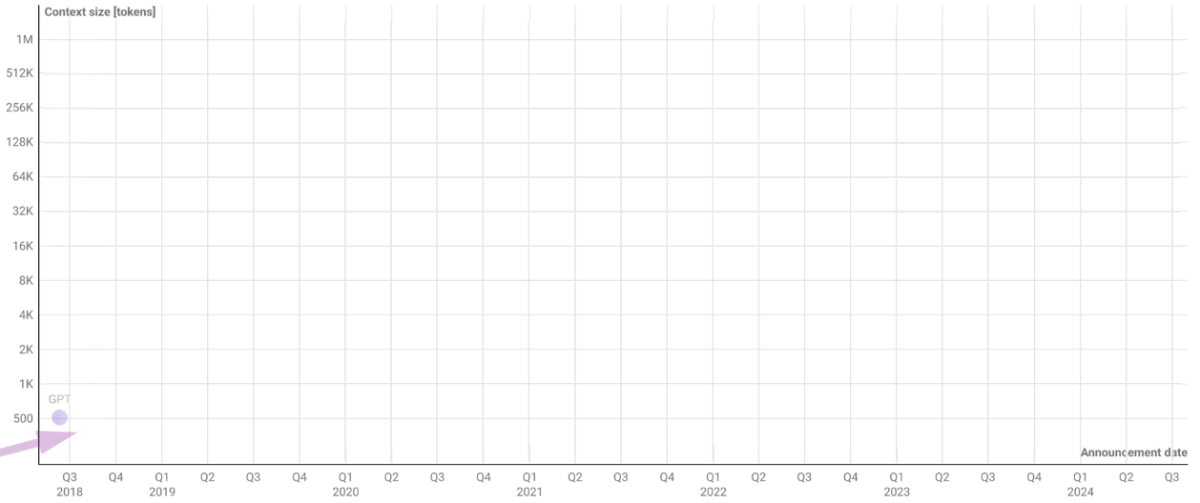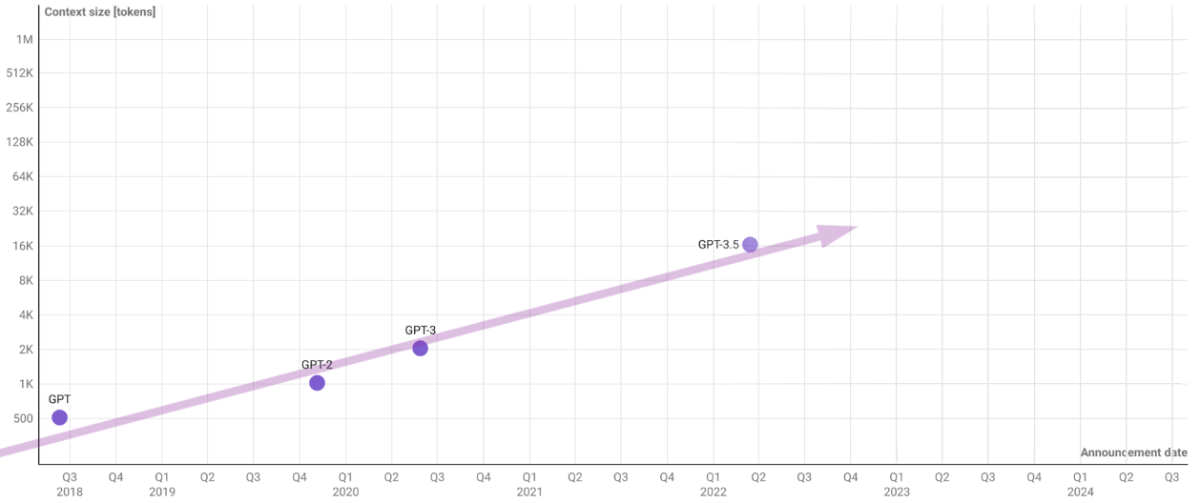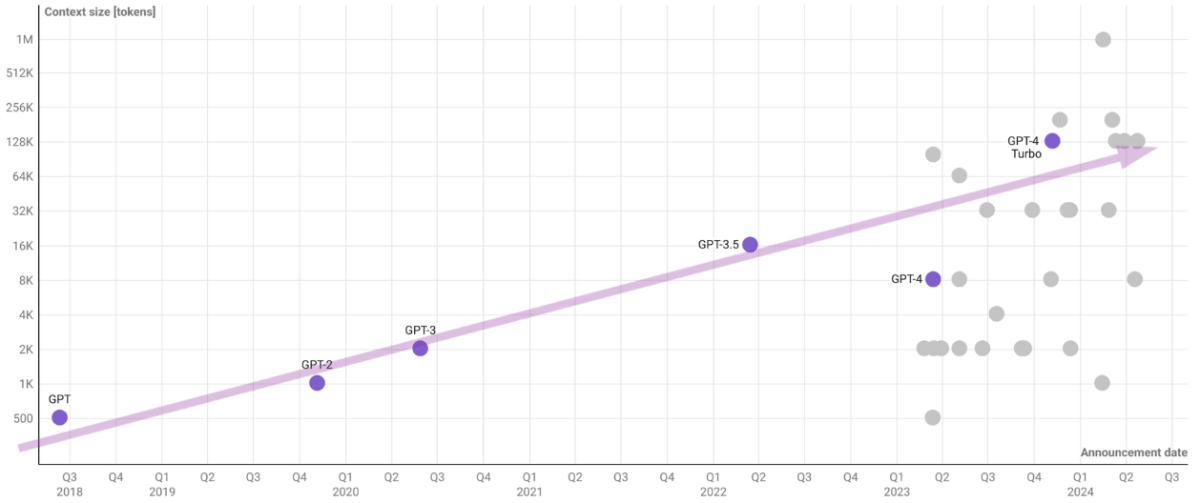
So now that we don’t forget things at midnight, what do we do with the smartest things we have ever created? Put them to work on creating data for their training data.
A new scaling law. Inference-time-compute.
Let's talk about a breakthrough that's reshaping AI: inference-time-compute, which is essentially teaching machines to reason. While this might sound like sci-fi, it all started with a simple observation about letting models take their time to think. The story of how we got here started in January 2022, well before we all started using chatGPT.
Think Step by Step. Chain of Thought
In 2022 DeepMind researchers started talking about how giving the model time to think would produce significantly better outcomes, especially in tasks that require reasoning. They called this Chain of Thought (CoT).
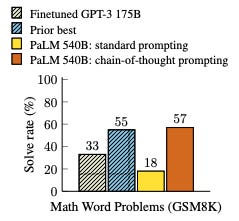
The impressive performance improvement caught everyone’s attention for mainly two reasons: it was very easy to apply - tell the model to take time to think (literally), and it was a performance improvement that came in inference time, as opposed to the expensive pre-training, which means the only cost was increased inference (OOM cheaper than pre-training).
Take Your Time.
This is where things get wild. Thanks to these massive context windows, our models no longer suffer from digital amnesia – they can actually hold onto thoughts for hundreds of thousands of tokens. But the real game-changer dropped in September 2024, when OpenAI unveiled their O1 family (after one year of speculations about Q* and Strawberry). These weren't just another batch of smart models; they were the first explicitly trained to think before they speak. Taking the CoT concept to its logical conclusion, OpenAI essentially taught GPT-4o to use every inch of that expanded context window, creating models that don't just respond but actually reason their way to better, more creative answers
Let’s take the classical Lex Friedman question and compare how a model trained to think and a crude model respond.

Now compare the beauty and nuance of the above response with the raw thinking of an intelligent base model, in this case, DeepSeek V3:

A New Scaling Law
When reasoning started to work, a whole new scaling law was unlocked. I talked about it in a couple of posts (1,2), so I won’t enter into detail, but in short, now we can push the performance of AI by both raw power (expensive and more complicated in each new generation) and using the LLMs to produce high-quality data via reasoning we can continue pushing what is possible with AI.
Reasoning was, in this regard, a paradigm shift. Instead of spending tons of compute in pre-training (which we continue to), a lot more compute was devoted to post-training, hoping that what comes out of reasoning allows us to continue improving our pre-training runs. Similar to what happened from GPT-1 to GPT-2 and GPT-2 to GPT-3, the first improvements were quick wins and low-hanging fruits. We went from O1-preview to O3 within 3 months, with massive performance improvements (I wrote at length about this here)

Reinforcement Learning as a Way to Teach Models to Think
This brings us to perhaps the most mind-bending discovery yet. DeepSeek's R0 team proved something revolutionary: models could learn to think using pure reinforcement learning without human intervention. Just set up the right environment and let the model learn. It was the Bitter Lesson playing out in real time – the simplest approach, allowing the model to learn through trial and error, turned out to be surprisingly powerful. The significance of this breakthrough was best captured by Andrej Karpathy, whose tweet perfectly crystallized why this matters...
Last thought. Not sure if this is obvious. There are two major types of learning, in both children and in deep learning. There is 1) imitation learning (watch and repeat, i.e. pretraining, supervised finetuning), and 2) trial-and-error learning (reinforcement learning). My favorite simple example is AlphaGo - 1) is learning by imitating expert players, 2) is reinforcement learning to win the game. Almost every single shocking result of deep learning, and the source of all *magic* is always 2. 2 is significantly more powerful. 2 is what surprises you. 2 is when the paddle learns to hit the ball behind the blocks in Breakout. 2 is when AlphaGo beats even Lee Sedol. And 2 is the "aha moment" when the DeepSeek (or o1 etc.) discovers that it works well to re-evaluate your assumptions, backtrack, try something else, etc. It's the solving strategies you see this model use in its chain of thought. It's how it goes back and forth thinking to itself. These thoughts are *emergent* (!!!) and this is actually seriously incredible, impressive and new (as in publicly available and documented etc.). The model could never learn this with 1 (by imitation), because the cognition of the model and the cognition of the human labeler is different. The human would never know to correctly annotate these kinds of solving strategies and what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome.
The true power of AI emerges in its “aha moments” when new information is created. And what these insights mean is that it is fed back into the AI, helping it refine itself in a continuous loop of improvement.
But for reinforcement learning (RL) to drive this cycle effectively, we must establish a verifiable way to measure success. What is a novel insight vs a well-crafted BS? What should be fed to the model, and what should we throw to the trash?
This is where the challenge arises: RL thrives in domains where correctness is objective and measurable—such as solving mathematical conjectures or playing a game—but struggles in areas where truth is subjective or ambiguous, like philosophical or artistic reasoning.
This constraint creates a bottleneck. We can only push AI so far within strictly verifiable domains before its learning potential starts to plateau. To break past this limitation, we need to find mechanisms that allow AI to explore and experiment beyond rigidly structured domains. Only then can we unlock the next frontier of machine-generated knowledge.
From AI Thinking to AI Acting. Agents and the world as a verifiable domain
The next frontier of AI learning is about action. So far, we’ve relied on verifiable domains like mathematics and programming, where AI’s outputs can be objectively evaluated. But what if AI could validate its own knowledge by interacting with the real world?
This is where agents come in. Unlike traditional LLMs, which generate answers in isolation, agents are designed to take meaningful actions—whether that’s booking a flight, researching complex topics, or even writing and executing code with minimal human intervention.
At first glance, deploying AI into the real world might seem chaotic. But in reality, the world itself acts as a verifiable domain. A well-booked flight is one that arrives at the correct destination, at the right time, within the given constraints. A $1M ARR business can be verified by looking at the accounting books. A well-coded program either runs correctly or doesn’t. Driving a car successfully means not crashing. These tasks provide natural success metrics, making them perfect training grounds for AI.
So, it’s now time to let the agents explore. This scenario has a double implication: the first is the obvious, massive economic gains, and the second, and not so obvious, an almost infinite source of novel knowledge.
AI Agents Will Unblock Massive Economic Gains.
AI agents that work - firstly in narrow domains and later for general purpose - will unblock massive economic gains2.
Narrow domain agents, the beginning
OpenAI claims that Deep Research can automate close to 10% of Expert-Level High Value Tasks. Even if this is an exaggeration, consider where we were just a year ago.

Klarna’s AI-powered customer support replaced 700 agents, demonstrating AI’s efficiency in transactional tasks.
Devin, the coding agent, automates software development, proving that AI can execute complex, multi-step processes with minimal supervision.
Broad domain agents
There are also broad domain agents. Agents that, in theory, should be capable of conducting multiple tasks autonomously. The most well-known one is OpenAI’s operator. These are agents that theoretically should be able to complete or assist on any task. These are still far from perfect and fail in many tasks, but they give us a glimpse of the future.
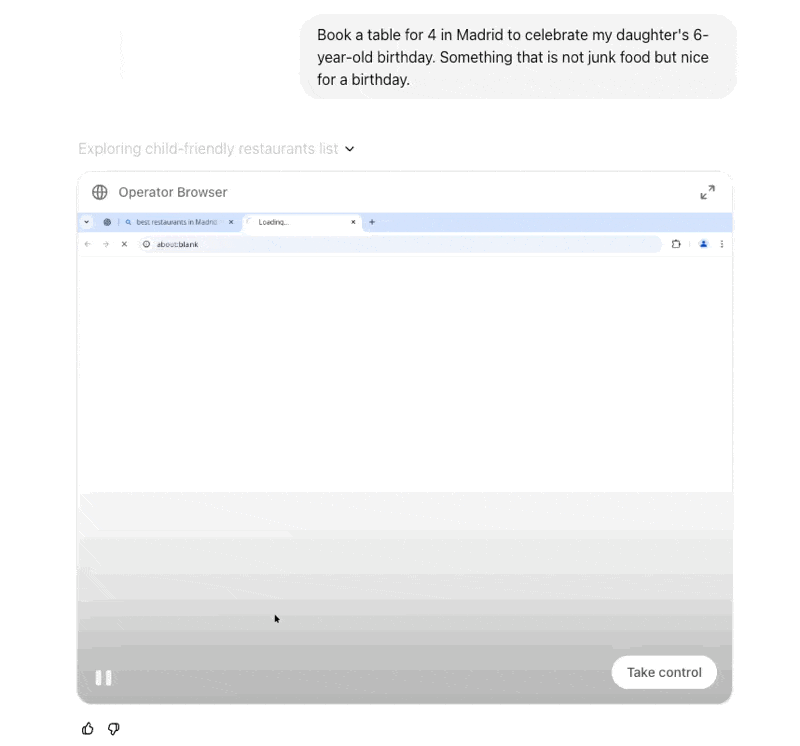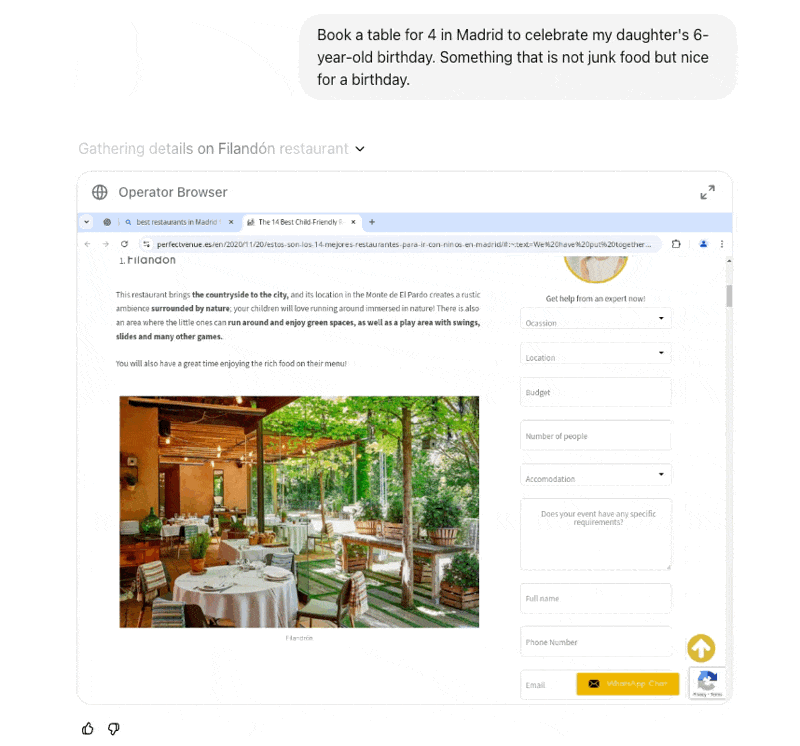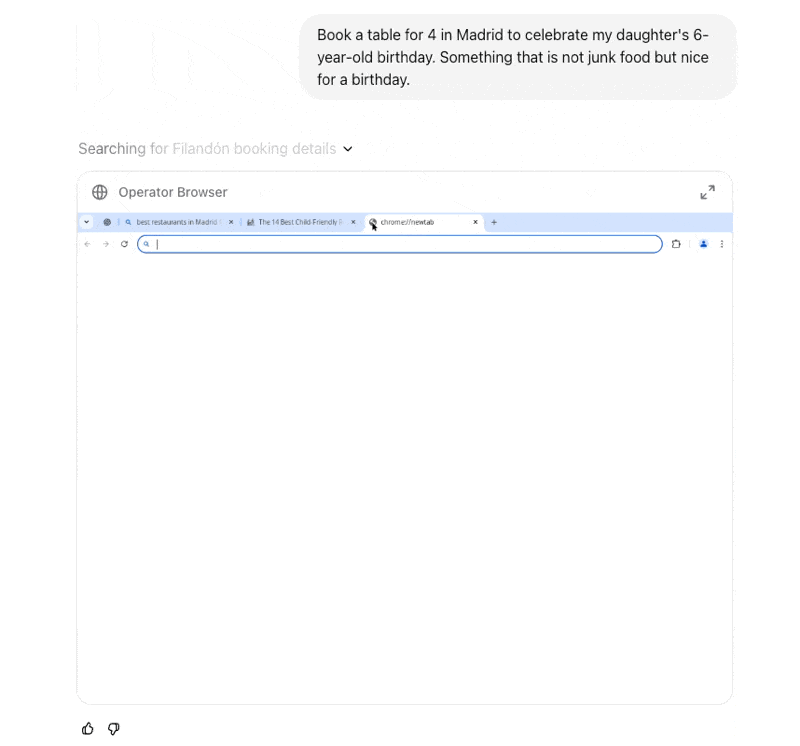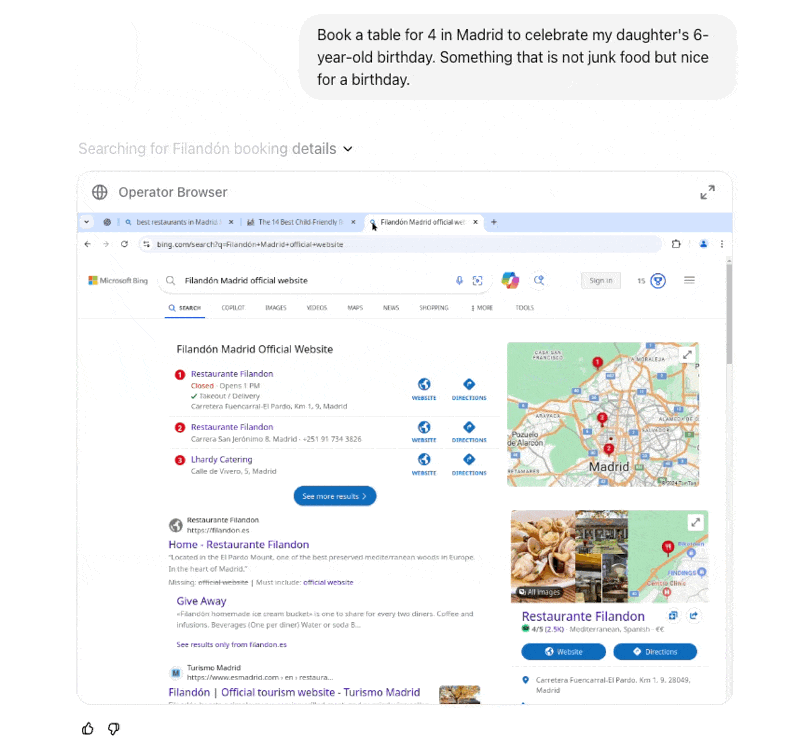
While agents are powerful, they’re not ready to be let loose on the world without safeguards. This is why AI labs are investing in simulations and sandboxes—controlled environments where AI can safely test its abilities. From OpenAI’s rumored internal agent simulations to models like Veo 2 and Sora, these testbeds provide the bridge between today’s reasoning-heavy AI and tomorrow’s real-world action takers.
Verifiable tasks
The second, and not that obvious consequence, is that the world becomes a verifiable domain. Tasks completed in the real world will have a direct, measurable outcome.
Now, all of a sudden, the 1M tokens of the context take a whole new dimension. If you let the agents interact with the world, the amount of new data becomes almost infinite, data that will revert back to the models.
Piecing all the parts together
Sam Altman wrote in a recent post.
We are now confident we know how to build AGI as we have traditionally understood it
I'll be the first to admit that this is a simplified view, and each piece I've touched on deserves its own deep dive. Could some of these steps fail? Absolutely. But the exciting part isn't in the details – it's that we can finally see a coherent path, one that's concrete enough for AGI labs to pursue with real conviction.
Sometimes the most complex ideas get explained in the simplest moments. As I was putting the final touches on this post, my daughter watched me fix her Lego set. “How do you know how to do that?” she asked. My response was instinctive: “I don't know, just did it a bunch of times.” Her response was brilliantly simple: “so you just try until it works.” Without knowing it, she had just summarized decades of AI research.
And that's it. We've trained LLMs to know virtually everything, but knowledge alone isn't enough. Like the turtle in the tale, human progress inches forward slowly – but now we have a chance to accelerate it. Not through mere imitation, but by letting AI generate novel insights through endless trial and error, creating more and more 'Move 37' moments that push beyond human imagination.
We may or may not be witnessing the early steps toward AGI, but Pascal's Wager3 has never been more relevant: if there's even a tiny chance we're on this path, the implications are too massive to ignore.

A token is how an LLM represents a word or a part of it. There is normally a relationship - depending on the language - between 1-2 tokens per word. For this post, I will use them interchangeably.
Massive economic gains is what I argued in other posts that will be needed to justify the continuous investment in AI
Pascal's Wager argues that believing in God is a rational choice since the potential benefits of being right (infinite reward) far outweigh the costs of being wrong (finite loss). Similarly, the potential impact of AGI is so massive that even a small probability of success warrants serious attention and investment.
Can totally relate to that when my kiddo asks for help with Legos, "how can you do that, did you know that or did that when you were a child?" and I have to encourage him stating, "never did that before.. just tried it, sometimes observing before trying and sometimes trying and then observing".
Personally, there is nothing more pleasing than watching kids, how they learn to see, how to make AI learn and grow. Recall this from Kevin Kelly's statement a few years ago about - AI is like a child - certainly a very simplified version, but has some merits.
Excellent write-up. Thanks for sharing..