


Beyond the Wrapper: How Luzia Delivers High-Quality AI Efficiently
While some might call us just a ‘wrapper,’ we’re much more than that. Luzia delivers a best-in-class AI experience to users who aren’t just…

While some might call us just a ‘wrapper,’ we’re much more than that. Luzia delivers a best-in-class AI experience to users who aren’t just looking for AI — they’re looking for a great experience. And who are those users? 99.9% of the world.
Consumer companies like ours are constantly exposed to the “votes” of our users, which means we obsess over delivering high-quality experiences. Once users form habits, they need a very strong reason to change. It’s a topic for another post to expose what people who call companies “wrappers” really mean, but for now, let’s dive into how we maintain our edge.
From the beginning, our focus at Luzia has been on delivering a high-quality product efficiently. When we started with GPT-3.5, it was the best available model, albeit expensive. Over time, we’ve tested and used various models, including GPT-4.0 Mini (with exclusive early access), GPT-4, Claude, Llama 3, and Mixtral. Here’s a quick snapshot of our performance and cost efficiency:
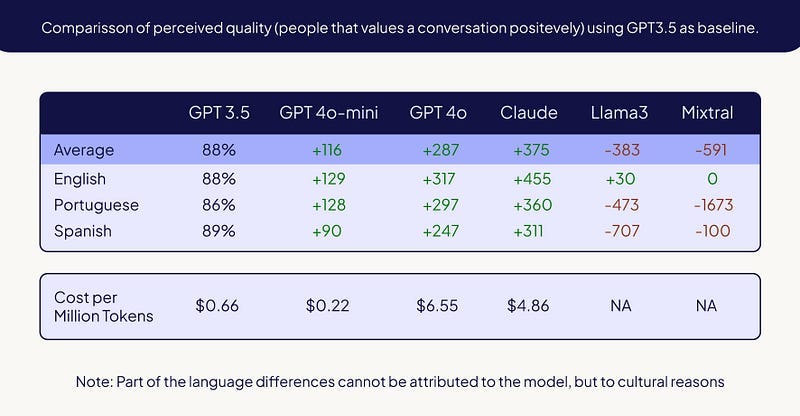
We’ve learned a lot along the way. While top-performing models like GPT-4 and Claude offer exceptional quality, especially for complicated use cases, the gap in performance was smaller than we would have expected by looking to public benchmarks like MMLU or LMSYS. This is likely due to the specific use cases of Luzia users. Despite their impressive capabilities, their high costs make them impractical for large-scale consumer use. The differences in perceived user satisfaction (PRR — users giving us thumbs up to a conversation divided by total votes) don’t always justify these costs. Efficiency is key, and we focus on optimizing for cost without compromising on quality.
One of the key aspects of our efficiency is our smart use of models. We don’t rely on a single model for all tasks. Instead, we classify the intent of each user query and route it to the most suitable model. For example, questions that require detailed knowledge might be sent to GPT-4o, while more general conversation could be handled by a more cost-efficient model (We even change it based on user life-cycle!). This approach allows us to maintain high quality while optimizing costs.
All the above are the driver of our journey from over $0.60 per user per month in inference to less than $0.15 while increasing quality, and engagement metrics 🤯. At the end of the day this balance between cost and quality is crucial, especially when handling 20 to 30 million messages daily.
Consider the cost implications: adding just a 65-token paragraph to our system prompt could cost an additional $24K a month at GPT-3.5 prices!!!
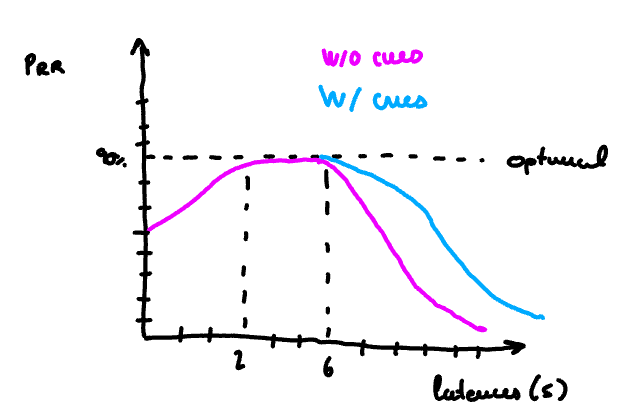
Through user feedback and extensive testing, we discovered that zero latency isn’t always ideal. A slight delay (2 to 6 seconds) gave us optimal results. Users perceive a short wait as indicative of a thoughtful, effortful response (1,2,3). Visual cues and intermediate messages further enhance this perception, allowing us to optimize throughput and costs. Research in human-computer interaction supports this, indicating that slight delays can improve user satisfaction by making interactions feel more deliberate and considered
Language performance is another critical factor. Models like GPT-3.5 and GPT-4.0 Mini excel in multiple languages, whereas others like Llama 3 (which was a HUGE improvement from Llama 2) and Mixtral struggle, particularly in Portuguese. But the data shows that a good enough is enough. Hyperlocalization (using local variations of the same language, e.g., “carro” vs. “coche”) hasn’t significantly impacted perceived quality. Instead, cultural factors and different use cases drive PRR variations across countries more strongly. But, since we are good at prompt engineering — and that’s cheap- we anyway adapted to local dialects and preferences, enhancing user experience without significant changes in PRR or higher cost.
The industry often succumbs to what Aloña and I call the “Bluetooth Luggage Syndrome,” the tendency to continuously ship new features in the hope they’ll drive engagement. At Luzia, we play it smart. We rigorously test each feature and listen closely to user feedback, focusing on those that truly add value and sunsetting those that don’t. For example, initially users wanted to know the weather (that’s all Alexa is for!), we shipped, but quickly proved it was an unnecessary feature for our users. These quickly understood that the potential of Luzia is a more subtle sophisticated assistance. We analyze PRR, user retention, and usage statistics to ensure only impactful features remain, prioritizing agility and simplicity to avoid overcomplicating the user experience.
Additionally, some features can be expensive to develop initially, but the industry moves fast. We leverage our “We Play Smart” framework, exploring and testing advanced features like memory only when they become cost-effective. Our obsession with fast delivery and maintaining an edge drives us to sunset unnecessary features quickly, ensuring we remain a super-fast, efficient company without getting bogged down by unnecessary costs.
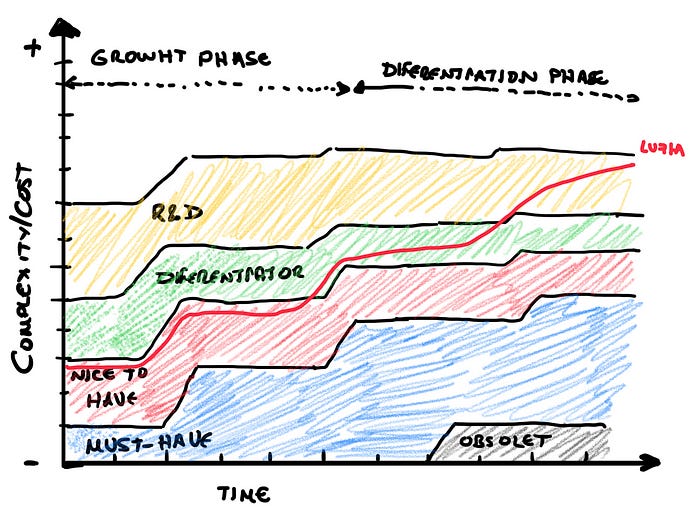
Looking ahead, we’re diving deeper into multimodality — handling documents, images, and voice efficiently — and exploring advanced features such as memory, and efficient tool utilization. We test these innovations thoroughly before rolling them out (some of them already in production for a small subset of users) to ensure they’re ready for prime time. Our pipeline is full of exciting ideas, and our commitment to innovation and efficiency ensures we stay ahead in the competitive AI landscape. There’s always more under the surface that we can’t share yet, but rest assured, we’re working on some very cool stuff.
Stay tuned or even better, join us!